- 软件



//

//

//

//

//

//

//

//

//

//
软件Tags:
在文本处理器中,如何提取通过正则表达式匹配的字符?对此,许多用户感到困惑,尽管网络上有诸多教程,但往往显得过于繁琐。如今,借助文本正则处理及规则导出工具,您可以轻松应对这一挑战。
文本正则处理及规则导出工具,亦称为文本文档批量处理导入导出大师,采用正则表达式进行文本提取,规则导出则运用作者独创的假规则,简称“假则”,提取内容可自定义!
例如,正则表达式提取出了六个子匹配项,其中第一个为:(.*?1),第二个为:(.*?2),第三个为:(.*?3)。规则可以直接如此使用。
规则包含三个要素,若有需求可进行添加:
n // 换行符
“文本内容” // "" 引号内为文本内容
(.*?1) //(.*?1) 中的 1 为子匹配项标识
示例:
提取正则:
(.*?)----(.*?)----(.*?)----(.*?)n
提取内容:
1--------何故----百度全家桶
2----吾爱看书----何故----百度文库
3----吾爱破解----啦啦----百度成精
4----吾爱破解----何故----吾爱睡觉觉
5----吾爱睡觉----何故----
6----吾爱破解----何故----天啊,好可怕
7----吾爱破解----何故333----百度不知道
8----你是谁啊----何故----百度知道454545645
10----吾爱破解----何故----百度知道
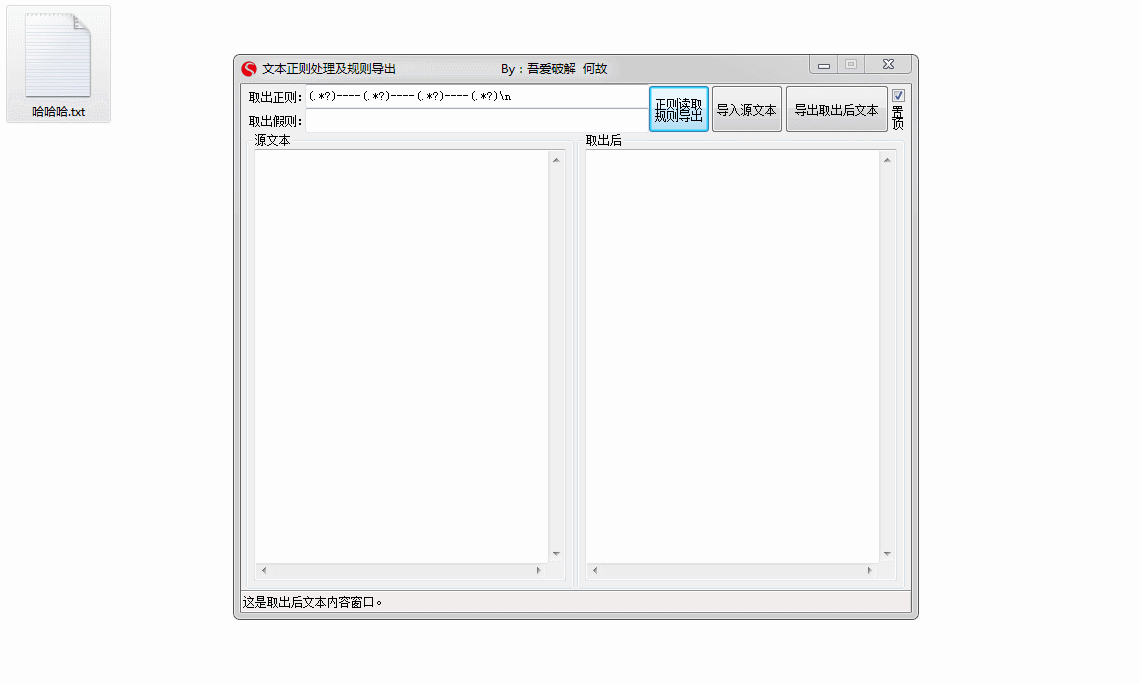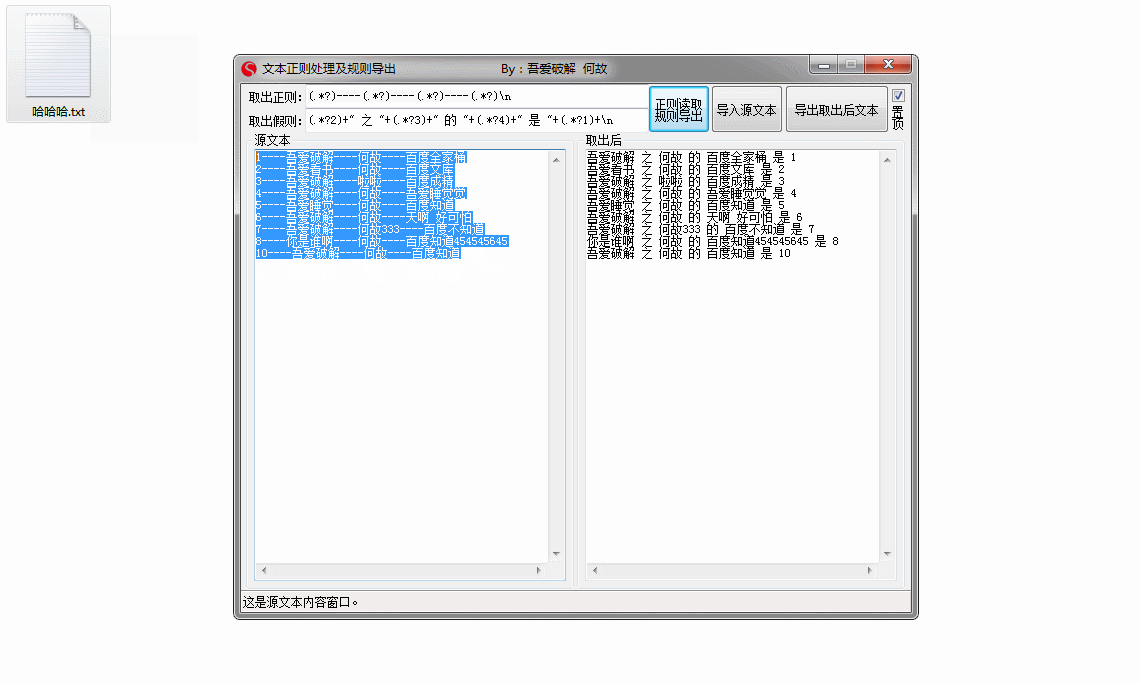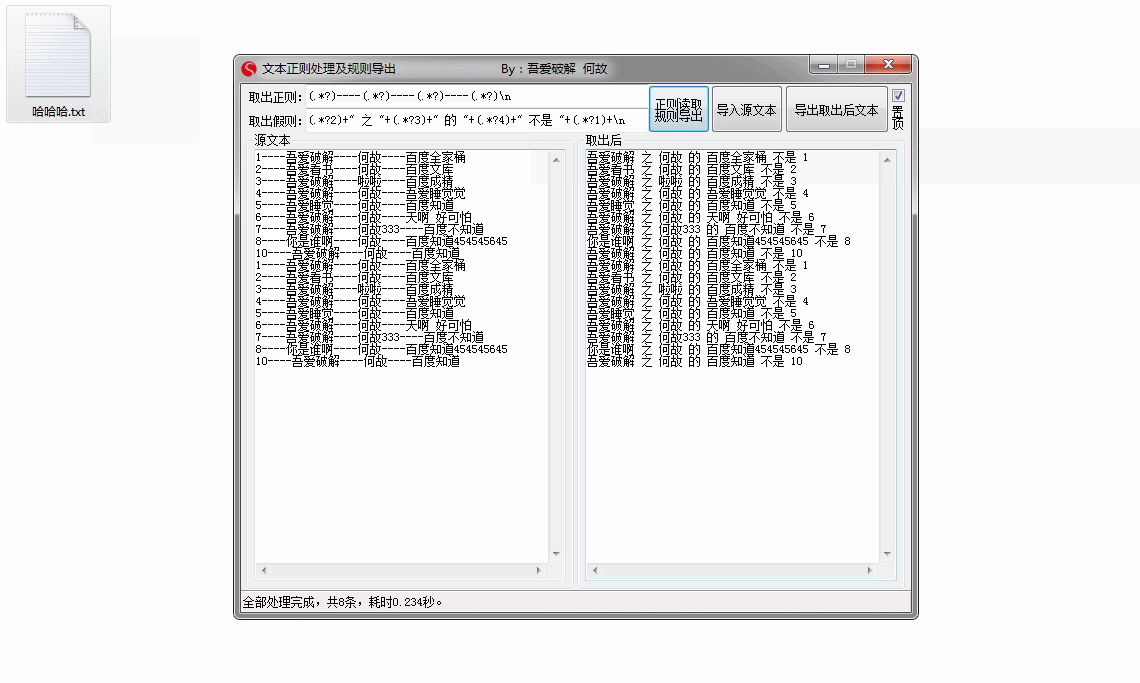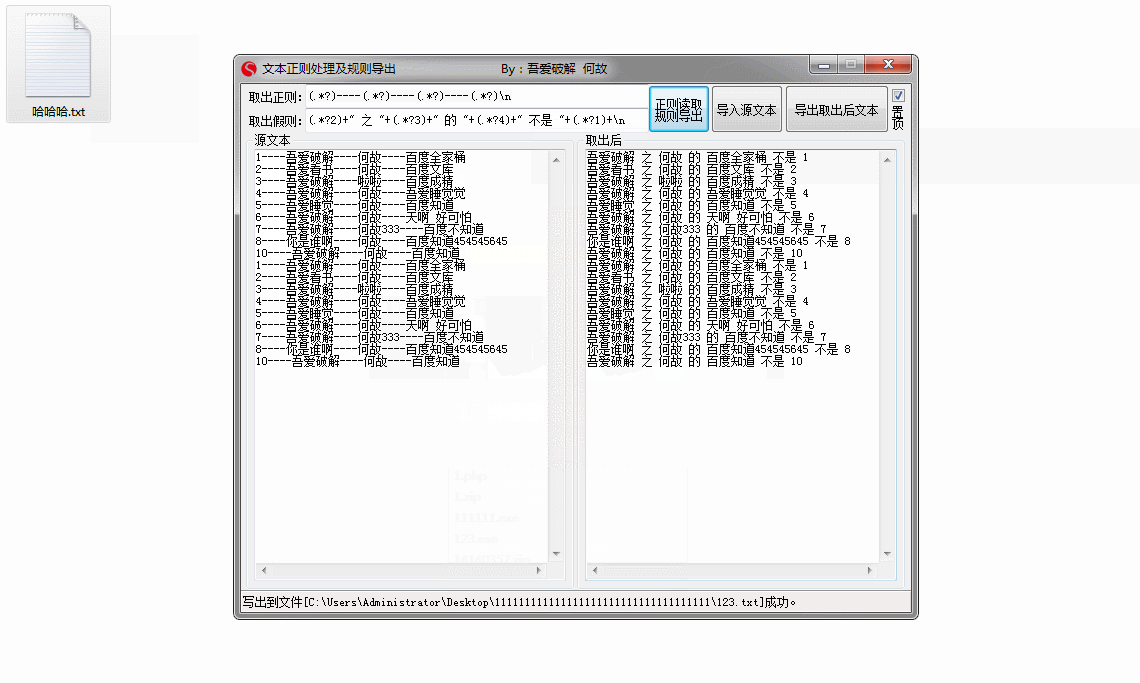
导出规则:
(.*?2)+"之"+(.*?3)+"的帖子【"+(.*?4)+"】是第"+(.*?1)+"个"+n
什么是正则?
正则表达式是一种对字符串操作的逻辑公式,它通过预先定义的一些特定字符及其组合,构成一个“规则字符串”,该字符串用于表达对其他字符串的过滤逻辑。
正则表达式是针对字符串(包括普通字符,如字母a至z之间的字符,以及称为“元字符”的特殊字符)进行操作的一种逻辑公式。它通过事先定义的特定字符及其组合,形成一个“规则字符串”,以此表达对字符串的过滤逻辑。正则表达式是一种文本模式,描述了在搜索文本时需要匹配的一或多个字符串。





 苹果iOS11 Beta3 更新固件体验版字体下载 / 1.95G
苹果iOS11 Beta3 更新固件体验版字体下载 / 1.95G 亿彩Pdf文档专用合并器字体下载 / 21.7M
亿彩Pdf文档专用合并器字体下载 / 21.7M 原木材积国标计算器字体下载 / 5.6M
原木材积国标计算器字体下载 / 5.6M 霍格沃兹入学通知书朋友圈二维码字体下载 / 22.8M
霍格沃兹入学通知书朋友圈二维码字体下载 / 22.8M CHERRY助手(樱桃机械键盘管理)字体下载 / 79.5M
CHERRY助手(樱桃机械键盘管理)字体下载 / 79.5M 齐心考勤机管理软件字体下载 / 20.8M
齐心考勤机管理软件字体下载 / 20.8M 拾趣规划电脑版字体下载 / 49.4M
拾趣规划电脑版字体下载 / 49.4M 手机号码处理软件字体下载 / 1.3M
手机号码处理软件字体下载 / 1.3M 谷歌浏览器 Google Chrome(集成常用扩展和脚本)浏览器类
谷歌浏览器 Google Chrome(集成常用扩展和脚本)浏览器类 刀魂TDv1.2.65正式版页游辅助
刀魂TDv1.2.65正式版页游辅助 我的世界1.8forge整合包手游辅助
我的世界1.8forge整合包手游辅助 微信pc版内测版QQ表情
微信pc版内测版QQ表情 全球顶级舞曲品牌下载器(RNBDJ最新网站音乐下载器)IP工具
全球顶级舞曲品牌下载器(RNBDJ最新网站音乐下载器)IP工具 博学宝E系列教育平台文件分割
博学宝E系列教育平台文件分割 精诚配件管理系统网吧管理
精诚配件管理系统网吧管理 Windows.UI.Xaml.Resources.rs2.dll系统优化
Windows.UI.Xaml.Resources.rs2.dll系统优化 微润格子秒表手机软件
微润格子秒表手机软件 京ICP备2024069179号-1
京ICP备2024069179号-1