- 软件



//

//

//

//

//

//

//

//

//

//
软件Tags:
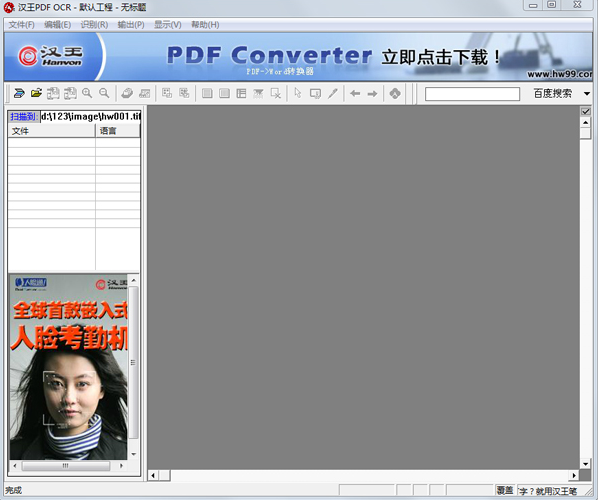
汉王,汉王所研发的创新软件,能够将图像中的文字转化为可复制、可粘贴的txt或word文件,极大地方便了用户,无需再逐字输入,轻松便捷。
新增了对PDF文件的打开与识别功能。
支持对文本型PDF的直接转换以及图像型PDF的OCR识别。
可通过OCR技术将PDF文件转化为可编辑的文档。
也可通过格式转换,将文字型PDF文件直接转化为RTF文件或文本文件。
1. 图像输入、图像前处理、预识别:
2. 图像输入:针对不同的图像格式,采用多样的存储方式,目前可利用OpenCV、CxImage等开源项目。
3. 预处理:主要包括二值化、噪声去除及倾斜校正等步骤。
4. 二值化:
- 对于摄像头拍摄的图片,大多为彩色图像,所含信息量极为丰富。为了使计算机快速、准确地识别文字,我们需将彩色图像处理为仅包含前景与背景的信息,将前景定义为黑色,背景定义为白色,这便是二值化图。
5. 噪声去除:
- 针对不同文档的噪声特征进行去噪处理,称之为噪声去除。
6. 倾斜校正:
- 用户在拍照文档时,往往较为随意,导致拍摄的图像不可避免地产生倾斜,需借助文字识别软件进行校正。
7. 版面分析:
- 将文档图片进行段落、行的划分,这一过程称为版面分析。由于实际文档形式的多样性与复杂性,目前尚无固定的最优切割模型。
8. 字符切割:
- 拍照条件的限制常导致字符粘连或断笔,这在很大程度上限制了识别系统的性能。
9. 字符识别:
- 该领域的研究由来已久,早期采用模板匹配,后续则以特征提取为主。由于文字的位移、笔画粗细、断笔、粘连及旋转等因素,特征提取的难度显著增加。
10. 版面还原:
- 人们期望识别后的文字,依然能如原文档图片般保持排列,段落、位置与顺序不变,输出至Word文档、PDF文档等,这一过程称为版面还原。
11. 后处理、校对:
- 根据特定语言的上下文关系,对识别结果进行校正,这便是后处理。
光学字符识别(英语:Optical Character Recognition, OCR)是指对文本资料的图像文件进行分析与识别,获取文字及版面信息的过程。OCR的概念最早由德国科学家Tausheck于1929年提出并申请了专利。随后,美国科学家Handel也提出了利用技术进行文字识别的设想。国内最早的OCR商业应用是由中国科学家王庆人教授在南开大学开发,并在美国市场上投入商业使用。
 闪电象剪辑工具音频处理 / 564KB
闪电象剪辑工具音频处理 / 564KB Easy2Convert EMF to IMAGE(EMF图片转换工具)音频处理 / 3.3M
Easy2Convert EMF to IMAGE(EMF图片转换工具)音频处理 / 3.3M Aiseesoft Video to GIF Converter音频处理 / 35.9M
Aiseesoft Video to GIF Converter音频处理 / 35.9M 龙卷风网络收音机下载音频处理 / 1.8M
龙卷风网络收音机下载音频处理 / 1.8M 六间房直播伴侣音频处理 / 2.2M
六间房直播伴侣音频处理 / 2.2M
 猫范家庭媒体中心MoreFunTV官方下载音频处理 / 72.7M
猫范家庭媒体中心MoreFunTV官方下载音频处理 / 72.7M 来疯直播伴侣音频处理 / 26.3M
来疯直播伴侣音频处理 / 26.3M 多媒体播放软件(XP Codec Pack)音频处理 / 24.9M
多媒体播放软件(XP Codec Pack)音频处理 / 24.9M 音乐电台客户端绿色版音频处理 / 1.1M
音乐电台客户端绿色版音频处理 / 1.1M Power Music Professional(音频编辑软件)音频处理 / 73.1M闪电象剪辑工具音频处理 / 564KBEasy2Convert EMF to IMAGE(EMF图片转换工具)音频处理 / 3.3MAiseesoft Video to GIF Converter音频处理 / 35.9M龙卷风网络收音机下载音频处理 / 1.8M六间房直播伴侣音频处理 / 2.2M猫范家庭媒体中心MoreFunTV官方下载音频处理 / 72.7M来疯直播伴侣音频处理 / 26.3M多媒体播放软件(XP Codec Pack)音频处理 / 24.9M音乐电台客户端绿色版音频处理 / 1.1MPower Music Professional(音频编辑软件)音频处理 / 73.1M
Power Music Professional(音频编辑软件)音频处理 / 73.1M闪电象剪辑工具音频处理 / 564KBEasy2Convert EMF to IMAGE(EMF图片转换工具)音频处理 / 3.3MAiseesoft Video to GIF Converter音频处理 / 35.9M龙卷风网络收音机下载音频处理 / 1.8M六间房直播伴侣音频处理 / 2.2M猫范家庭媒体中心MoreFunTV官方下载音频处理 / 72.7M来疯直播伴侣音频处理 / 26.3M多媒体播放软件(XP Codec Pack)音频处理 / 24.9M音乐电台客户端绿色版音频处理 / 1.1MPower Music Professional(音频编辑软件)音频处理 / 73.1M




 Letasoft Sound Booster(附激活码)录音软件
Letasoft Sound Booster(附激活码)录音软件 全球顶级舞曲品牌下载器(RNBDJ最新网站音乐下载器)IP工具
全球顶级舞曲品牌下载器(RNBDJ最新网站音乐下载器)IP工具 大华ConfigTool免安装IP搜索工具FTP软件
大华ConfigTool免安装IP搜索工具FTP软件 超级街霸2HD超清版(可单机/可组队/可对战)修改器
超级街霸2HD超清版(可单机/可组队/可对战)修改器 lspzipx.dll桌面工具
lspzipx.dll桌面工具 疯狂游戏大亨2模拟游戏
疯狂游戏大亨2模拟游戏 LizardSystems Remote Desktop Audit 21FTP软件
LizardSystems Remote Desktop Audit 21FTP软件 R15自动循环测试工具备份还原
R15自动循环测试工具备份还原 微信pc版内测版QQ表情
微信pc版内测版QQ表情 京ICP备2024069179号-1
京ICP备2024069179号-1